AI现状:基于100万亿Token的实证研究
作者:nunumick 发布时间:11 Dec 2025 分类: AI
说明:这是一份完全由 AI(豆包、Gemini、千问)生成的总结(包括配图),我只做了内容提取和对比整合工作。学习报告内容的同时也对比下主流模型及其 APP 的能力,原始报告来自 OpenRouter 平台,需完整内容可以看原文1。
研究基于对 OpenRouter 平台上超过 100 万亿 token 的真实 LLM 交互数据分析,提供了一个关于大型语言模型(LLMs)实际使用情况的经验性视角。
报告分析了 2024 年底至 2025 年间大型语言模型(LLMs)的真实世界使用模式。研究发现,随着 OpenAI 的 o1 等推理模型的推出,市场从单次文本生成转向了多步骤、工具调用和推理密集型的工作流程,即“代理式推理”正在崛起。数据揭示,尽管编程任务在所有 LLM 使用中占据主导且增长最快,但创意角色扮演却在开源模型(OSS)的使用中占据超过一半的份额,表明用户需求具有复杂的多样性。此外,报告还提出了“灰姑娘玻璃鞋效应”,即最早找到模型 - 工作负载完美契合的早期用户群体(Foundational Cohorts)会表现出显著且持久的留存率,这成为衡量模型价值的关键指标。整体而言,LLM 生态系统是多元化且竞争激烈的,闭源模型和开源模型分别在高价值和高容量任务中发挥作用,并且亚洲市场的份额正在迅速扩大。
研究基础背景
- 研究背景:2024 年 12 月 OpenAI o1 模型发布后,LLM 领域从单轮模式生成转向多步审慎推理,本研究基于 OpenRouter 平台超 100 万亿 token 的真实交互数据,填补了 LLM 实际使用场景的实证认知空白。
- 数据范围:覆盖 2024 年 11 月 - 2025 年 11 月(部分分类数据始于 2025 年 5 月),包含全球数百万开发者 / 用户、300+ 活跃模型、60+ 提供商,50% 以上使用量来自美国以外地区。
- 研究维度:开源 vs 闭源模型、智能体推理、任务分类、地理分布、成本 - 使用动态、用户留存六大核心方向。
六大方向核心发现
1. 模型生态:开源与闭源双轨并行
- 闭源模型仍占主导(约 70% token 份额),但开源模型稳步增长至 2025 年末的 30%,其中中国开源模型(如 Qwen、DeepSeek)从 1.2% 增至近 30%(部分周),平均占比 13%。
- 开源模型市场从 DeepSeek 垄断转向多元化,Qwen、Meta LLaMA、Mistral AI 等跻身前列,中等规模模型(150 - 700 亿参数)成为新热点,小型模型(<150 亿参数)使用率下降。
- 开源模型擅长创意角色扮演(占比 52%)和编程辅助(15 - 20%),闭源模型主导结构化商业任务。
2. 用法变迁:智能体推理崛起
- 推理型模型使用率从 2025 年初近乎为零增至超 50%,xAI 的 Grok Code Fast 1、Google Gemini 2.5 系列成为核心驱动。
- 工具调用呈持续上升趋势,Anthropic Claude、Google Gemini 等模型主导该场景,2025 年中后开源模型逐步入局。
- 交互复杂度提升:平均提示词 tokens 增长 4 倍(1.5K → 6K),输出 tokens 增长 3 倍(150 → 400),编程任务是长序列交互(超 20K tokens)的主要驱动。
3. 任务分类:编程与角色扮演主导
- 编程成为第一大任务类别,从 2025 年初 11% 增至近 50%,Anthropic Claude 系列占该领域 60% 以上使用量,OpenAI、Google 及开源模型逐步分流份额。
- 角色扮演是开源模型第一大用途(52%),闭源与开源模型在该场景占比接近(42% vs 43%),远超预期。
- 其他任务中,翻译、知识问答、教育占比有限,科学类查询多集中于机器学习 / AI 主题(80.4%),健康、金融类任务呈碎片化分布。
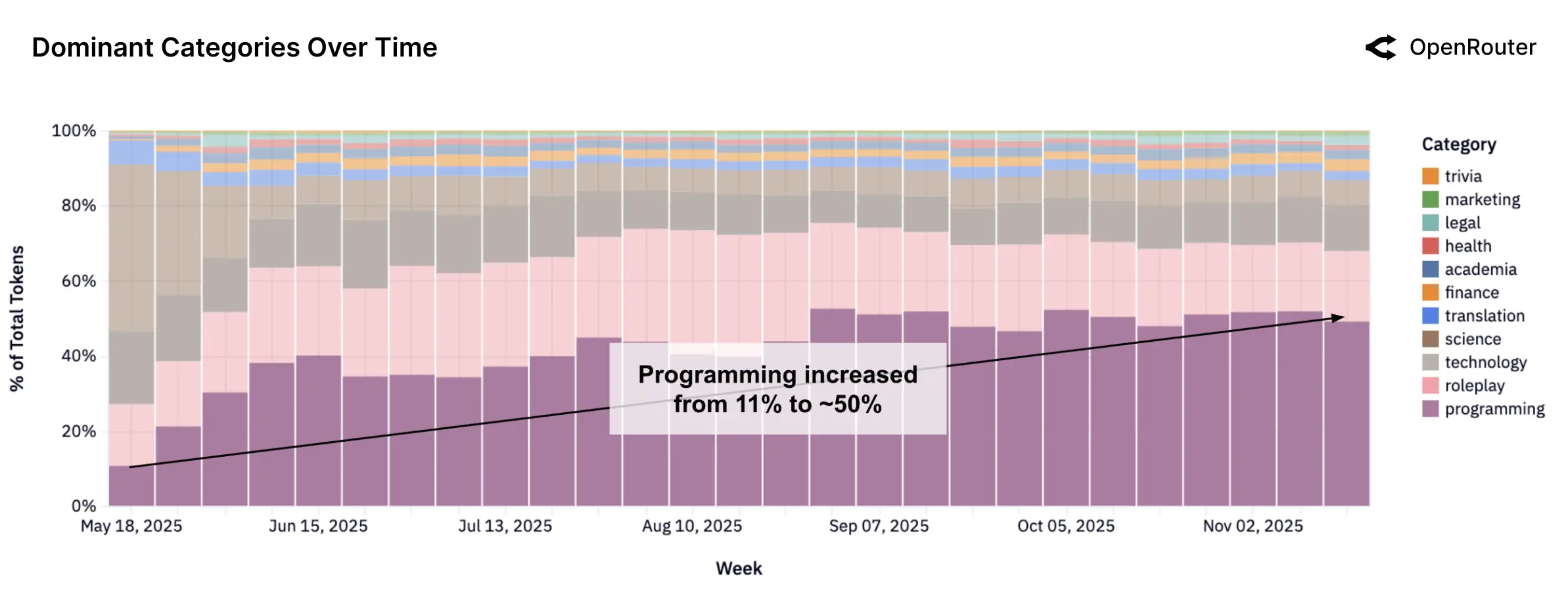
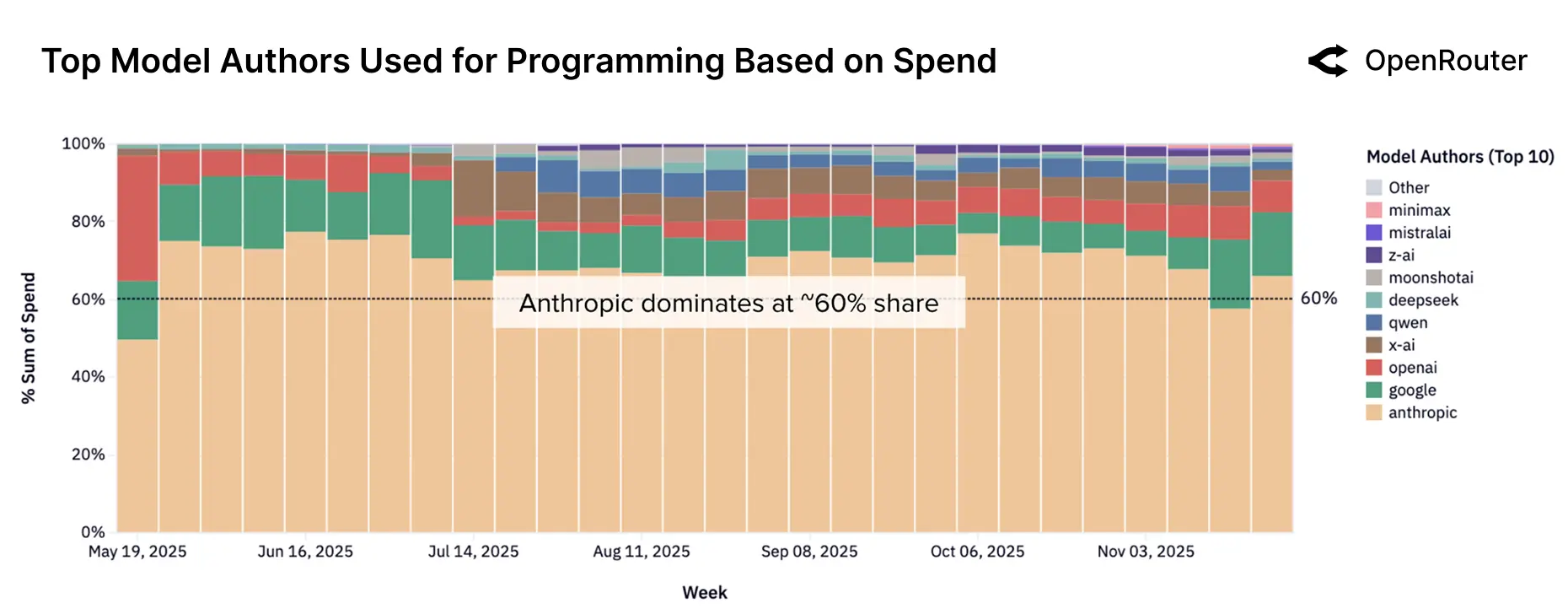
4. 地理与语言:全球分布多元化
- 北美仍为最大市场(占比 <50%),欧洲份额稳定(15 - 20%),亚洲占比从 13% 翻倍至 31%。
- 语言方面,英语占 82.87%,简体中文占 4.95%,俄语(2.47%)、西班牙语(1.43%)等构成次要语言。
5. 用户留存:灰姑娘“水晶鞋”效应
- 早期用户群体留存率显著高于后期用户,如 2025 年 5 - 6 月的 Claude 4 Sonnet、Gemini 2.5 Pro 用户,5 个月后留存率约 40%。
- 核心逻辑:模型与用户高价值需求实现精准匹配(“水晶鞋契合”),用户因技术适配、成本惯性形成强锁定,DeepSeek 模型出现“回流效应”(流失用户回归)。DeepSeek 模型曲线中表明一些流失用户在尝试替代品后,发现 DeepSeek 在特定的工作负载中提供了最优的匹配,因此选择回归。
6. 成本 - 使用:非完全价格敏感
- 市场分为四大象限:编程 / 角色扮演(高用量低 cost)、技术 / 科学(高用量高 cost)、金融 / 健康(低用量高 cost)、翻译 / trivia(低用量低 cost)。
- 需求价格弹性弱:10% 降价仅带来 0.5 - 0.7% 用量增长,闭源模型占据高价值高 cost 领域,开源模型主导高用量低 cost 场景。
- 质量与可靠性优先于价格,Anthropic Claude、OpenAI GPT - 4 等高价模型因性能优势保持高使用率。
模型任务的专业化
根据 OpenRouter 平台的实证数据,不同模型提供商及其模型类型在任务适配性上呈现出显著差异。模型提供商的使用模式显示出明显的专业化倾向。没有单一模型能够主导所有用例,用户根据模型的能力、延迟、价格和信任度进行选择。
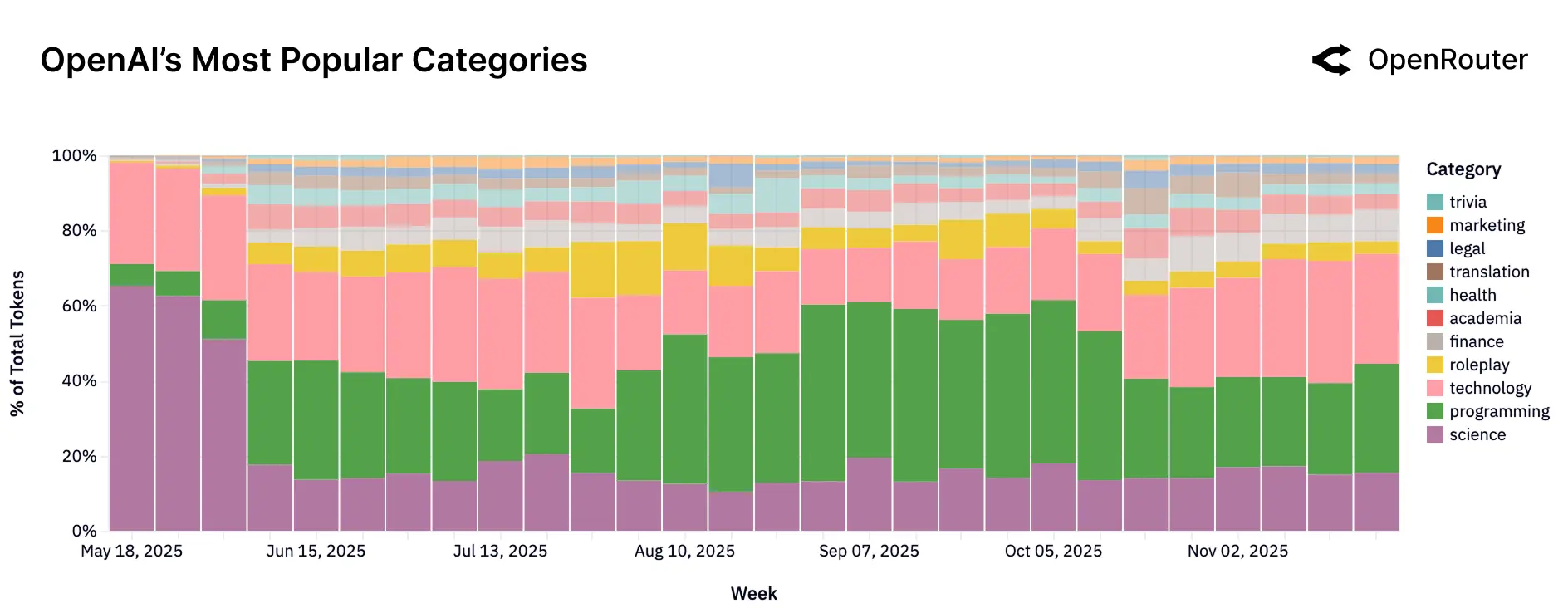
Anthropic(Claude 系列)主导编程与技术任务,其模型专为复杂推理、编码和结构化工作流优化,企业用户广泛将其用作开发助手;在编程相关支出中,Anthropic 持续占据超过 60% 的份额,其总使用量中编程与技术任务合计占比超过 80%。
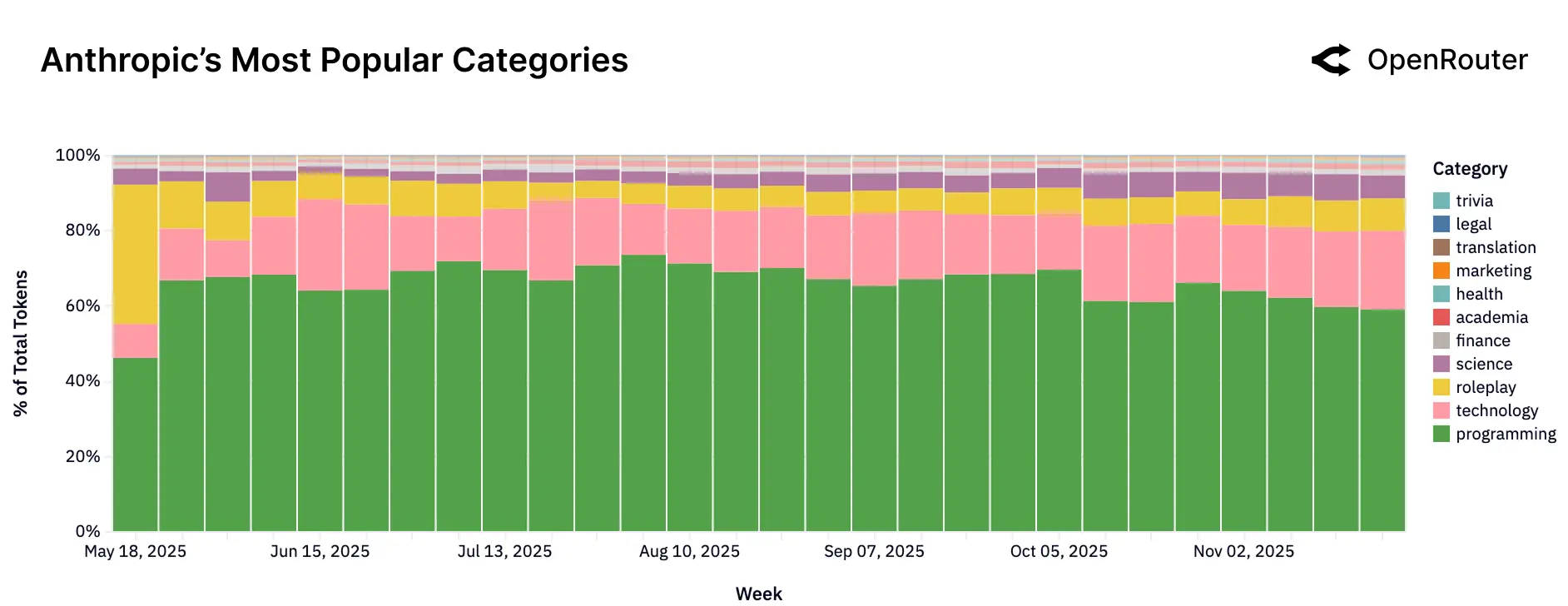
DeepSeek(开源模型)则明显偏向消费端应用场景,尤其聚焦于角色扮演和休闲互动,展现出高参与度的对话特性,其角色扮演类使用通常占总使用量的 66% 以上。
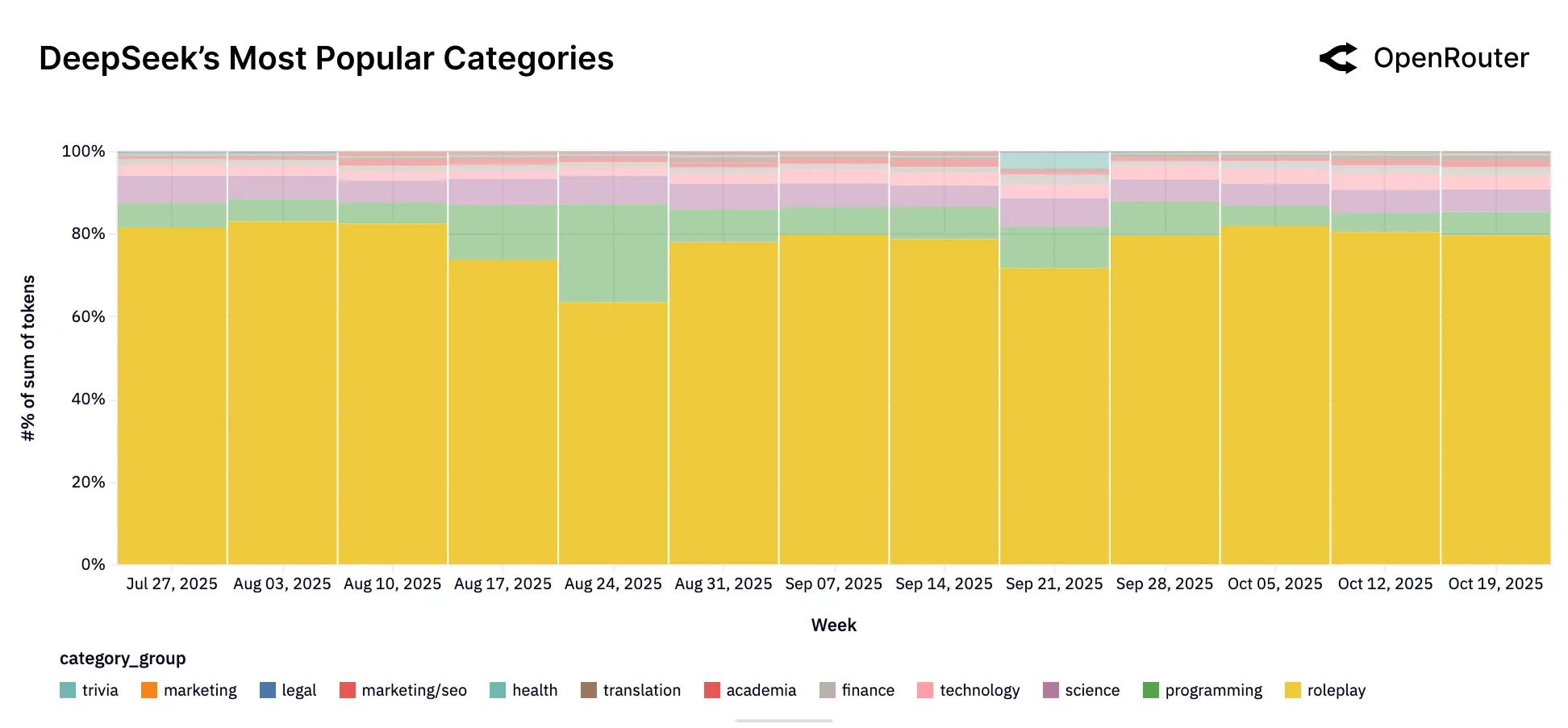
相比之下,Qwen(开源模型)显示出对技术和开发者任务的明确侧重,在开源生态中直接参与技术领域的竞争,其编程任务占比稳定在 40% 至 60% 之间。
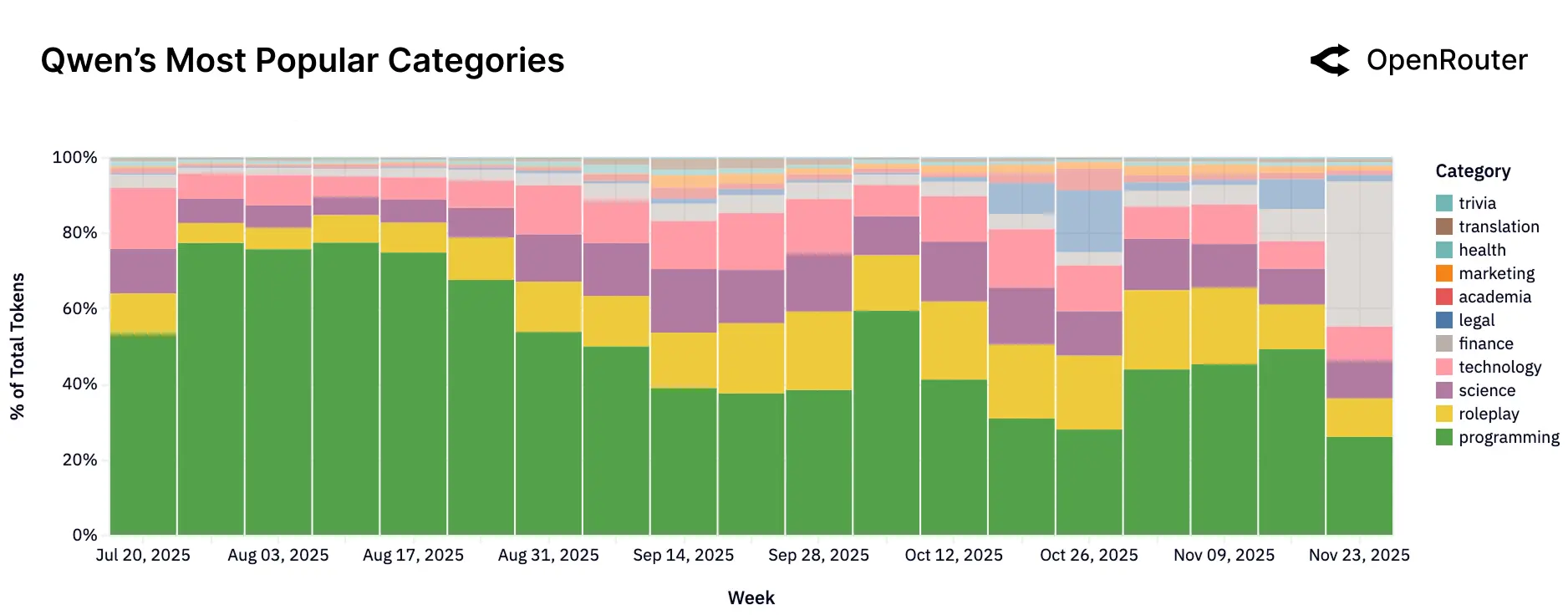
OpenAI(GPT 系列)的使用模式已从早期多样化的科学或休闲用途,逐步转向高价值、结构化的专业场景,如今主要服务于开发者工作流和企业级应用,编程与技术任务合计占比超过 50%。
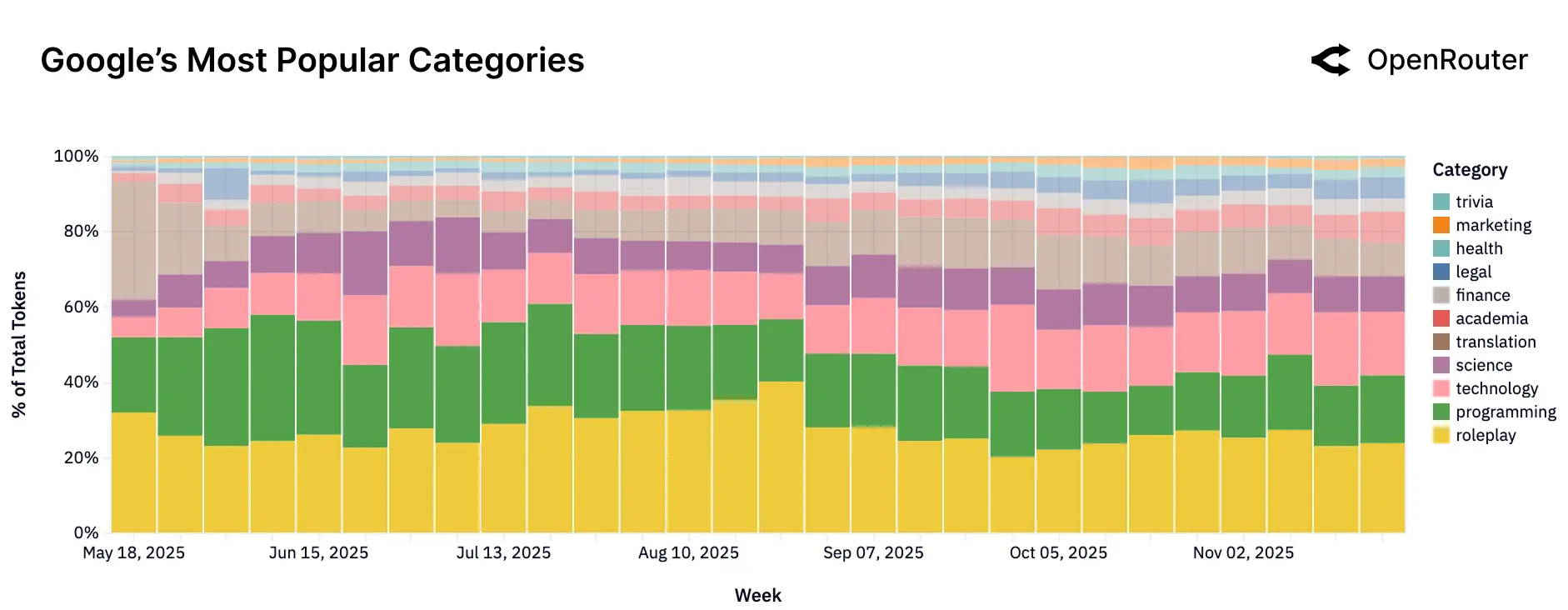
Google(Gemini 系列)的使用分布更为多元,涵盖翻译、科学、通用知识问答等多个领域,但其在编程任务中的份额相对较低,并呈下降趋势,截至 2025 年底,编程仅占其总使用量的约 18%。
xAI 的早期使用高度集中于编程领域(占比超 80%),后期随着免费流量的涌入,任务类别才逐渐拓宽。
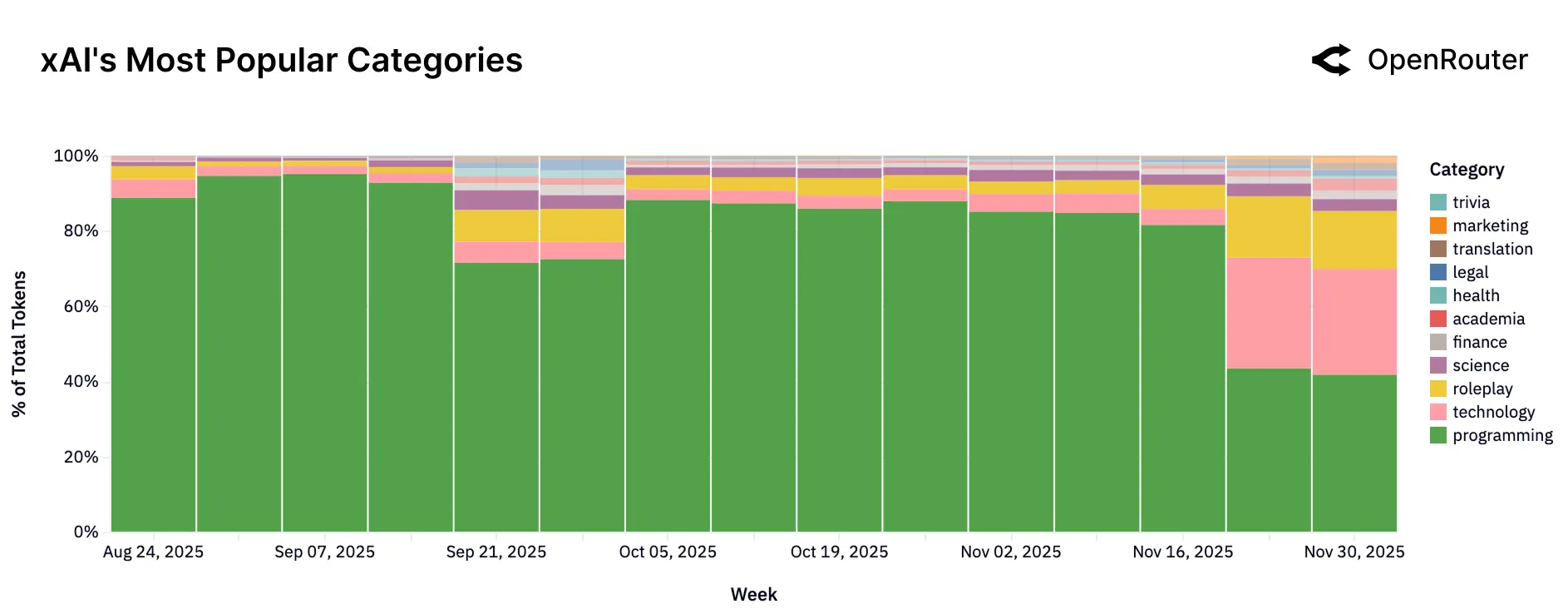
一般开源模型(包括其他地区及中国开源模型) 的生态优势体现在两大方向:一是创意型角色扮演(占所有开源模型使用量的约 52%),二是成本敏感型的编码辅助任务,反映出开源社区在娱乐互动与开发者工具两个维度上的双重活力。
整体来看,市场已形成一个分层结构:
- 闭源(专有)模型(如 Anthropic 和 OpenAI)凭借其可靠性、卓越的推理能力和信任优势,在高价值、与收入相关的工作负载(特别是复杂的编程和技术任务)中保持主导地位和定价权。
- 开源模型(如 DeepSeek 和 Qwen)则通过提供成本效益和定制化,在大众市场驱动型用量(如角色扮演)和高容量编码辅助任务中占据巨大份额。这使得 LLM 生态系统具有结构上的多元性,用户在不同的能力和成本平衡中进行选择。
我们可以将当前的 LLM 市场理解为一个大型的专业工具箱。就像一个工程团队会针对不同的工作选择不同的工具一样:对于需要最高准确性和可靠性的核心项目(例如构建系统架构),他们会选择昂贵的专业级闭源工具(如 Anthropic Claude);而对于需要大量重复操作或创意自由的任务(例如编写测试脚本或进行角色扮演),他们则会选择高效率、低成本的开源工具(如 DeepSeek 或 Qwen)。
进一步对观点进行提炼
关键范式转变: LLM 领域经历了重大转折,正在从单次文本生成转向多步骤的智能体推理(Agentic Inference),涉及内部审议、潜在规划和迭代细化。推理优化模型的 token 使用份额在 2025 年迅速上升,现已超过总使用量的一半 。这一转变也体现在工作负载的复杂性增加上,平均提示 token 长度增长了近四倍,主要驱动因素是编程工作负载需要处理大量的上下文信息。
生态系统结构与竞争: LLM 生态系统是结构性多元化的,闭源和开源模型都占据了重要份额。虽然专有模型仍占多数 token 使用量,但开源模型已稳步增长,到 2025 年末达到总使用量的约三分之一。尤其值得注意的是,中国开源模型(Chinese OSS)迅速崛起,其增长态势和迭代速度重塑了开源领域,并在某些周内达到了所有模型总使用量的近 30%。开源模型的市场格局正走向碎片化,多个模型家族共同维持可观的使用份额,而不再由单一模型主导。
主要应用领域: 实际使用情况复杂且多面,最主要的活动集中在编程辅助和创意角色扮演两大类别。在所有 LLM 查询中,编程是增长最快且占主导地位的类别,在最近几周内占总 token 量的比例已超过 50%。对于开源模型而言,角色扮演占据了超过一半的使用量,这表明用户利用开源模型的定制化和内容限制较少的特点,主要用于互动对话和创意场景。
经济与留存模式: LLM 市场的需求对价格相对缺乏弹性,但模型的使用情况存在显著的市场细分 。闭源模型通常占据高成本、高使用量的“卓越领导者”象限,用于高价值或任务关键型工作负载,而开源模型则倾向于低成本、高使用量的“高效巨头”领域,满足成本敏感型需求。模型的长期留存由“灰姑娘的水晶鞋”效应决定,即早期用户队列一旦发现模型与特定工作负载完美匹配,就会形成持久的参与度,抵抗后续模型更迭带来的替代效应。
地域分布: LLM 使用量正变得越来越全球化和去中心化。北美仍然是最大的单一地区,但在大部分观察期内占总支出的比例不到一半。亚洲地区的份额显著增长,目前已达到约 31%。全球竞争的下一阶段将取决于模型的文化适应性和多语言能力。
有什么关键启示
豆包模型辅助总结
- 模型生态趋向多元化,多模型集成成为开发者首选,而非单一依赖。
- 消费级娱乐(角色扮演)与专业生产力(编程)同为 LLM 核心需求,模型评估需兼顾创意性与实用性。
- 智能体推理成为竞争核心,工具调用、长上下文处理、多步推理能力决定模型上限。
- 全球市场与多语言支持成为必备能力,中国开源模型在全球竞争中占据重要地位。
- 留存率比短期增长更关键,“首次精准匹配”是模型长期占据市场的核心优势。
千问模型辅助总结2
- 开源生态重构:中国开源模型通过快速迭代和本地化优势,与西方模型形成双寡头竞争格局,DeepSeek、Qwen 等模型在代码生成领域表现突出。
- 代理式推理革命:推理模型使用量突破 50% 大关,工具调用频率年增 300%,标志着 LLM 从文本生成向任务执行范式转变。
- 应用场景颠覆认知:角色扮演类应用占据开源模型 52% token 份额,编程类应用呈现 “长上下文 + 短输出” 特征,平均输入 token 达 6K。
- 市场突破密码:灰姑娘玻璃鞋效应揭示,模型市场突破的关键在于解决特定工作负载的 “技术 - 经济约束”,而非单纯性能领先。
总而言之,该研究通过大规模数据揭示了 LLM 正在成为跨域(从编程到创意写作)的基本计算基质。未来的竞争将取决于运营卓越性、对真实任务完成度的衡量,以及对多模型、多语言生态的适应能力。
参考资料
标签:
llm
<<< EOF